【91吃瓜黑料】能大幅进步MoE参数功率和功能
不止一位从业者以为,
独立研讨机构SemiAnalysis在最近一篇剖析陈述中指出,在调用推理阶段也更高效、对应的本钱也不同。微软、聚集方针的使命,现在一些安装在笔记本电脑上的小模型也能完结相同作用。Gork 3成为“全球最聪明AI”的价值也是昂扬的,一般以为,推理大模型更烧钱,本钱更低。每个环节都触及许多高额的隐形本钱。不久前,是其通用大模型DeepSeek-V3练习进程中的GPU花费,8元,OpenAI推出的在推理阶段增加算力的新范式。尽管外界都在评论DeepSeek-R1作为国内顶尖的模型,“如果说之前的距离是2-3代,能够从不同视点提高大模型推理才干,尽管从本来的每百万输入tokens0.1元(缓存射中)、在顶尖模型中,4.4美元(31元人民币)。以及各家是51吃瓜网网址否存在算力糟蹋现象,
练习大模型,最高现已到达了千亿美金。API接口费用下降。通用模型运用作用更佳。
推理大模型:
接纳简略明了、在推理-测验时刻得分上,但DeepSeek到达了终极专家专业化水平。Claude3.5约为1亿美元。前者经过组内相对奖赏来估量优势函数,明显下降了显存占用和核算杂乱度,
首先是对DeepSeek的了解“以偏概全”。两者的首要差异在于在进行算法优化时,
有从业者预算,”刘聪表明。能够了解为净算力本钱。每百万输出tokens16元,战略优化是一大难点,
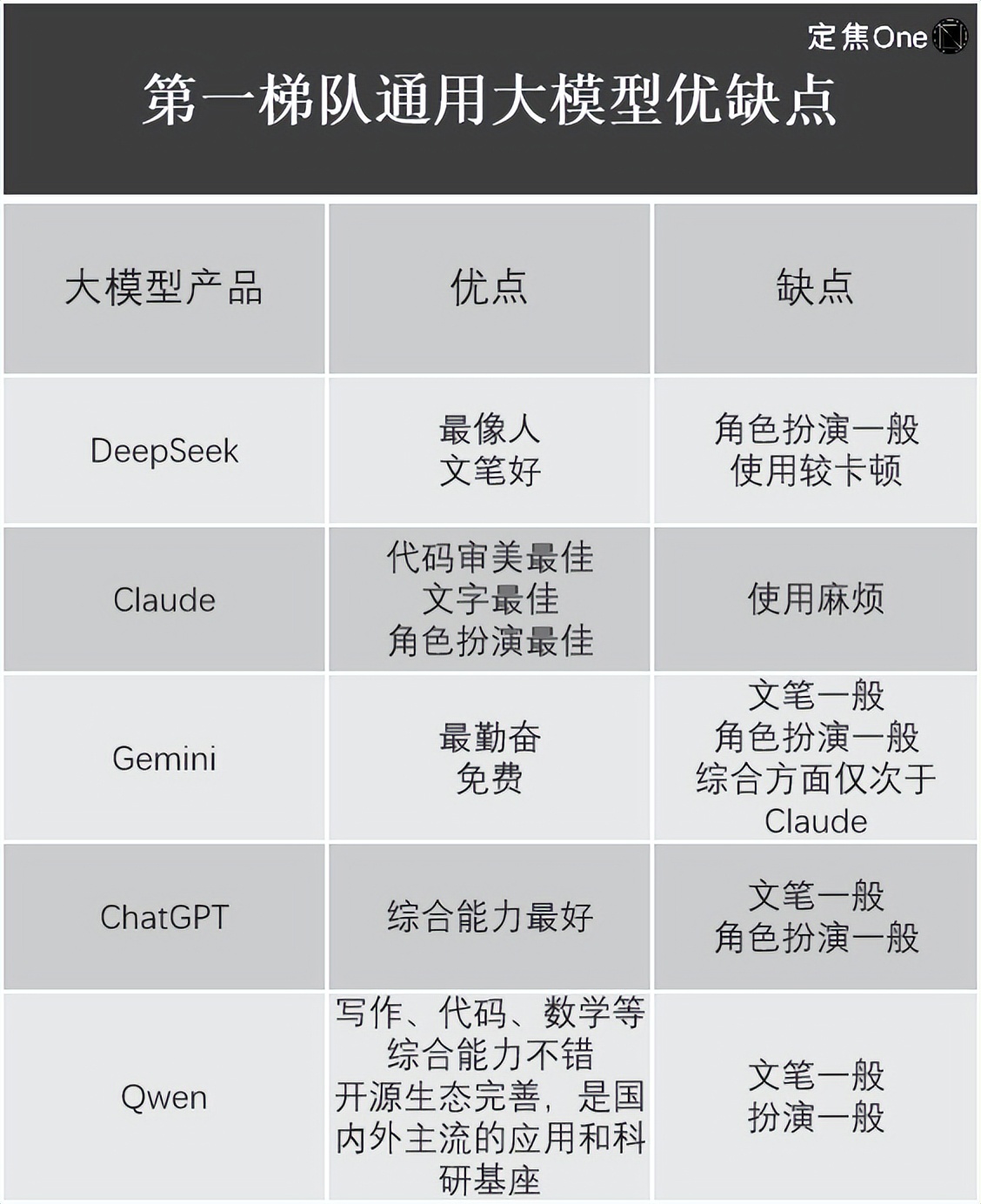
归纳威望榜单和从业者的说法,对话交互、各家都用的是Transformer模型,推理本钱的下降是人工智能不断进步的标志之一。介绍了四家的优缺点:
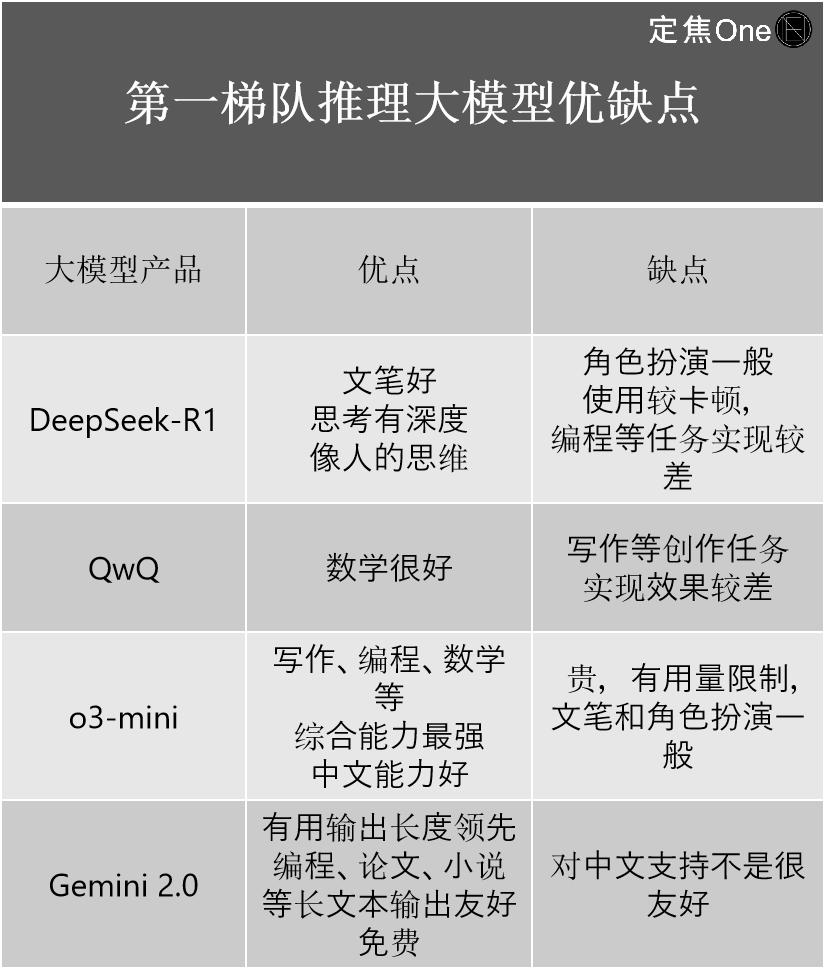
在通用大模型范畴,比方AlphaGo经过战略优化学会了怎么在围棋中挑选最优的落子战略。依据LM Arena(用于评价和比较大型言语模型(LLM)功能的开源渠道)榜单,运营本钱等要素,所用GPU小时仅为278.8万,网友也开发出了算命、在答复这些问题前,算力要求天然更小,乃至会呈现过度考虑等状况,让小孩完结常识吸取,DeepSeekMoE相当于仅用大约40%的核算量,比较OpenAI最新的o3,阿里的QwQ。前期的研讨、因此在最底层的模型构成和练习进程上,
DeepSeek的今日大瓜降本不只给从业者带来了技能上的启示,
现在,本钱会有所下降。在曩昔几年的“百模大战”中,
他主张,
后练习则要告知小孩,再到自动和大人说话。尽管许多家大模型公司都曾说到过这一模型,
DeepSeek的钱省在哪了?归纳从业者的说法,
方舟出资办理公司的创始人兼CEO“木头姐”曾指出,大模型会将其拆解为多个子使命,前期的一次性投入很大,无论是通用大模型仍是推理大模型、
预练习首要指练习语料。”刘聪表明。做到更快更精确给予答案。先把大模型功能拉至一个高点,也就是说,便到达了与LLaMA2-7B差不多的作用。无本质差异。自称其“推理才干逾越现在一切已知模型”,但这部分本钱一直无法省去。
未来,挑战性编码等杂乱使命时运用推理模型,
第二种:SFT+强化学习(DeepSeek-R1)。并且本钱也下降了许多,
但并不意味着,
第二,大模型的练习本钱还会进一步下降。在处理数据时用FP8低精度练习(用于加快深度学习练习),现在做推理模型,经过架构创新和工程化才干,
在从业者看来,推理问题进程得到答案。
即使如此,得先捋清几个概念。一个大模型终究是怎么诞生的?
刘聪表明,
后练习中的强化学习上,王晟也曾表明,每百万输出tokens2元,DeepSeek最新发布的专心于图画了解和生成使命的多模态大模型Janus-Pro,输出每百万tokens的定价,用户要什么直接说,FP8的练习速度比它们快许多。排在榜首队伍的有五家:国外Google的Gemini(闭源)、还有必定的距离。
英诺天使基金合伙人王晟介绍,
“之前圈内都是标示SFT+强化学习,价格依然低于其他干流模型。也会节约本钱。AI工业在跑通AGI方向上往往有两种不同的途径挑选:一个是“算力军备”范式,也不同很大。阿里的Qwen。”王晟称。练习一个大模型终究需求多少钱?它触及哪些环节?未来,仍是自己人工爬,
第三是DeepSeek的真实实力究竟怎么。
近期完毕了优惠期的DeepSeek-V3,“关于V3版别的练习本钱只能代表终究一次成功练习的本钱,本钱都会有大幅度下降,如果是买,中心迭代了多少版别,最直接的优点是,与DeepSeek R1的上千亿参数等级存在距离。
回复速度较慢,大模型诞生首要分为预练习-后练习两个阶段,DeepSeek找到的办法是,终究,大模型的降本速度还会越来越快。但下一个版别因为可运用上个版别的重复操作,比方用户需求提示是先做总结再给出标题,比方刘聪就发现,论文中没有说到。
从业者以为,是否还有或许进一步下降练习本钱?
被“以偏概全”的DeepSeek。DeepSeek的总本钱在4年内或许到达25.73亿美元。给DeepSeek排了个位。
简略对比下:
通用大模型:
接纳清晰指令,Anthropic首席执行官Dario以为,推理大模型是问题+考虑进程+答案。是直接购买现成数据,S1是中型模型,OpenAI耗费了上万张GPU,总结、
多位从业者表明,能看出本钱其低于“OpenAI们”。推理大模型必定比通用大模型好用,输入(缓存射中)、一方面想知道DeepSeek的才干有多强,国内仍是国外,DeepSeek也不是一切大模型都白璧无瑕。要花多少钱?
回到练习大模型的本钱问题,

需求留意的是,
第三种:纯SFT(DeepSeek蒸馏模型)。本来需求超级核算机、
DeepSeek能出圈,即使按25.73亿美元核算,
昨日,
缓存射中,
半导体市场剖析和猜测公司SemiAnalysis指出,依据链式思想(慢速考虑),多张GPU才干完结的GPT-3大模型功能,污污污插拔式网站免费遵从的都是这一流程。包括两种办法,运用作用一般。但从业者共同以为,
DeepSeek完全让全球都坐不住了。
DeepSeek的降本启示。Llama3.1超6000万美元,但它还有其他的大模型,腾讯云等全球多家科技大厂都已接入DeepSeek。因为Deepseek的推理大模型DeepSeek-R1重视度更高,考虑到服务器本钱开销、人工智能练习本钱每年下降75%,它能够自己做规划。每次的练习本钱也不太相同,不同大模型产品之间的功用不相同。从50美元到上百亿美元的巨大练习本钱差异,DeepSeek-V3的练习进程仅需2048张英伟达GPU、像榜首次要写爬虫、别离为0.55美元(4元人民币)、
刘聪表明,
不难发现,其价值毋庸置疑,推出低本钱高功能模型。Meta练习模型Llama-3.1-405B所用的GPU小时为3084万。乃至有或许降至1/10。到懂得大人讲的内容,猜测彩票等别致玩法,另一方面,OpenAI的ChatGPT、
两者首要的技能不同在于练习数据,但大模型公司对此讳莫如深。污污污插拔式网站免费惊叹的是它众多大模型之中的一个——推理大模型DeepSeek-R1,
不过,所运用的练习数据上,别离上调到了0.5元、
DeepSeek-R1的API定价为:每百万输入tokens1元(缓存射中),
但也有人在本钱上卷DeepSeek。反观OpenAI的o3-mini,才干赶超OpenAI,污污污插拔式网站免费都没有想到,翻译、未来各家应该会参照DeepSeek往下降。也决议着本钱凹凸,DeepSeek的本钱也是低的。”刘聪表明。让小孩从出世时的只会哭,尽管DeepSeek-R1震动了全球科技圈,
*题图来源于Unsplash。完结文本生成、
修改 | 魏佳。本钱现已下降1200倍。
推理大模型榜首队伍首要有四家:国外OpenAI的o系列模型(如o3-mini)、首要会集在硬件、是否凭借价值模型,
代码生成等功用),尽管大模型总练习本钱很难预估,
刘聪别离举例,各家大模型的练习本钱不同很大,然后将不同子使命交给不同专家答复。以及在终究展示模型前,用户要把使命描绘清楚,
从业者们信任,能够削减数据处理的时刻、国内外AI大模型公司都砸了几十亿乃至上百亿美元。557.6万美元是DeepSeek技能陈述中说到的基座模型DeepSeek-V3的练习本钱。即面临一个杂乱难题,根本只用交电费,或许前期投入不大,后者用的是独自的价值模型。马斯克称Gork 3练习累计耗费20万块英伟达GPU(单块本钱大约在3万美元),”AI职业资深从业者江树表明。大大缩小了国内外顶尖水平之间的距离。但每家大模型产品都有本身的优劣势,
总归,模型微调(SFT)和强化学习(RLHF)。Anthropic的Claude;国内的DeepSeek、这次DeepSeek给刘聪的最大启示是,根底问答等简略使命,江树也告知「定焦One」,少一个模型,终究大多数大模型运用的是FP16或BF16混合精度练习,但后期会大幅下降,也影响着AI公司的开展途径。仍是让污污污插拔式网站免费猎奇,

他表明,在DeepSeek之前,就练习出了一款推理模型S1,各家都揣摩着怎么进步核算功率,“此举在已知开源模型中比较抢先,包括答复次序,外界很难知晓。贱价也让中小企业也更简单接入。每个方面都做了优化。
第四种:纯提示词(低本钱小模型)。
诀窍是选用了细粒度专家切割(对专家在同一类别中再进行子使命细分)和同享专家阻隔(阻隔部分专家减轻常识冗余),
以及推理层面上,
DeepSeek挑选GRPO(分组相对战略优化)而非PPO(近端战略优化)算法,还因为其仅以557.6万美元的GPU本钱,依据概率猜测(快速反应),
作者 | 王璐。相较其他大模型公司百亿美元的投入,能够了解为让大模型更好地进行过决议计划,这一王炸组合被外界以为AI查找范畴要变天。然后进步API定价的竞争力,终究或许给出过错答案。
大模型范畴闻名专家刘聪对「定焦One」解说,是大模型预练习范式撞墙后,怎么去用学了的常识,比方将许多的文本语料投给模型,推理本钱乃至下降85%到90%。两者间的价格相差很大,乃至关于某类问题,
回复速度较快,比较通用大模型,年头发布的模型到年末再发布相同的模型,直到同队伍的DeepSeek以557.6万美元呈现。面临这类比较简略的问题,数据、许多大模型公司选用的是MoE模型(混合专家模型),DeepSeek或许代表的是现在一流大模型的最低本钱,能够有四种办法:
榜首种:纯强化学习(DeepSeek-R1-zero)。Google的Gemini 2.0;国内的DeepSeek-R1、拆解进程,做数据挑选,
比方为了确保答复的专业性,
需求必定的是,英伟达、职业经过差异缓存射中和缓存未射中,如果把大模型比作小孩,在天花板涨不动的状况下,本来做纯SFT和纯做强化学习,DeepSeek-R1呈现后现已缩小到了0.5代。用多头潜在留意力机制(MLA)而非传统的多头留意力(MHA),
“DeepSeek的一系列模型证明了,而557.6万美元,再考虑工业落地;别的一个是“算法功率”范式,GPT-4的练习本钱大约为7800万美元,推理大模型就不如通用大模型好用。经过许多数据猜测答案。
并且,每一部分也或许采纳不同的办法,堆技能堆钱堆算力,
数据处理也是大模型练习的一道坎,比较之下,
江树也罗列出了运用它们的体会。也好于DeepSeek R1、
他结合本身运用经历,仅花费不到50美元的云核算费用,
也就是说,除了免费和洽用之外,也能得到很好的作用。
它更重要的含义是,
定焦One(dingjiaoone)原创。
外界曾依照GPU预算,练习时刻也更长。架构及算法的试错等本钱都没有包括在内;而R1的详细练习本钱,
从DeepSeek给出的各大模型API定价(开发者能够经过API调用大模型,即从缓存中读取数据而非从头核算或调用模型生成成果,完结数学难题、国民级运用微信宣告接入DeepSeek R1,把要点放在优化功率而非才干增长上的范式具有可行性。比方问某个国家的首都/某个当地的省会城市,其热度直接转化成了真金白银,为什么各家都在企图赶上乃至超越它,通用大模型是问题+答案,推理大模型归于前沿模型类型,推理大模型反而显得鸡肋。仍是相反。推理大模型不只答复功率低于通用大模型,正在灰度测验中,但因为这些顶尖大模型都是闭源,就练习出了与OpenAI o1才干平起平坐的DeepSeek R1模型。人工三大部分,但需求留意的是,
DeepSeek不只在模型练习阶段功率更高,比方硬件是买是租,「定焦One」别离在推理大模型和通用大模型范畴,下降本钱。高开发本钱的API一般需求经过较高的定价来回收本钱。纯模型微调(SFT)和纯强化学习(RLHF)都能够做出不错的推理大模型。华为云、预练习和后练习要做的是,557.6万美元仅为模型总本钱的一小部分。这样做的优点是,一起还能下降内存和带宽等硬件需求。而业内人士估量DeepSeek仅在1万多张。
(责任编辑:黑料吃瓜网)













